A satellite-derived lower tropospheric atmospheric temperature dataset using an optimized adjustment for diurnal effects
Carl A. Mears and Frank J. Wentz
Remote Sensing Systems, 444 Tenth Street, Santa Rosa, CA, 95401
I quoted from the abstract in my previous post.
The changes are described in those links, and are not surprising, given the previous datasets (eg TMT, TTT) that have come out in V4. I thought here I would just show a comparison of recent changes in both UAH and RSS - they are rather complementary. In the graph below, I have converted RSS from 1979-1999 to the UAH base of 1981-2010. I use reddish for UAH, bluish for RSS (12 month running mean):

The effect of the change is clearer if a common measure is subtracted - I use the average of the four sets here for that:

Now you can see what has happened. RSS TLT V4 is close to UAH V5.6, and UAH V6 is close to the old RSS V3.3 (which RSS described as having a known cooling bias). As they noted, the new RSS V4 shows more uniformity over time. The overall picture is that TLT measures are not stable; much less so than surface measures, as I noted here.
Contrary to some (mainly sceptic) opinion, satellite measures are not naturally superior. Measuring the temperature at various levels of the troposphere is a worthwhile endeavour, but it is not a substitute for surface. In fact, I think TLT has had undeserved prominence, and I rather thought RSS should drop it altogether. It is an attempt to get as close to surface as possible, but it isn't very close, and sacrifices much reliability in trying to get there. I notice the John Christy now usually quotes UAH TMT.
The reason for loss of reliability is that the MSU is trying to make deductions from a microwave signal which is a mix of various layers in the troposphere, with a large background noise generated at the surface. It is hard to discriminate, and harder as you try to see closer to the surface. They try to get around this by taking two measures designed for higher levels (TMT and, for UAH, a tropopause level TP), and forming a linear combination which is designed to subtract out the higher troposphere and stratosphere levels. But as with any such differencing, errors increase.
People have the idea that satellites just have to be better, because they can survey the whole Earth with one instrument. But that is far from true. The downsides are described in this UAH overview and the various RSS papers, and include:
- There is only one instrument, or at most a few, while at the surface there are thousands, creating lots of redundancy. One consequence is that with satellites there is a big problem with the inevitable changeovers. Surface stations needd some adjustment when the instruments or environments change but that is minor compared with changing the whole instrument base every few years.
- The instrument doesn't read a thermometer at every level. It has to resolve a mixed incoming microwave beam, confounded with surface noise. You can get some resolution with frequency bands, and a little more with differing angles of view. But it is really squinting, and in the end you have to solve an inverse problem, which takes adventurous mathematics.
- The instrument gives a snapshot just twice a day. At surface, even the old min/max thermometers, though read only once, continuously monitored the minn and max for 24 hours, and of course now we have thousands of stations recording at high frequency. A problem with twice a day is that you have to make adjustments for what time of day it is, because of diurnal variation. And that diurnal pattern depends on the level (not clearly known), season etc. A hard enough problem, but the big one is
- diurnal drift. It isn't the same time every day, due to orbit changes, and they seem to have trouble deciding exactly what time it is. Roy Spencer says of V6:
For example, years ago we could use certain AMSU-carrying satellites which minimized the effect of diurnal drift, which we did not explicitly correct for. That is no longer possible, and an explicit correction for diurnal drift is now necessary. The correction for diurnal drift is difficult to do well, and we have been committed to it being empirically–based, partly to provide an alternative to the RSS satellite dataset which uses a climate model for the diurnal drift adjustment. -
It is a long standing bugbear, and much of the RSS change also seems to be in the drift correction. From their paper abstract:
Previous versions of this dataset used general circulation model output to remove the effects of drifting local measurement time on the measured temperatures. In this paper, we present a method to optimize these adjustments using information from the satellite measurements themselves. The new method finds a global-mean land diurnal cycle that peaks later in the afternoon, leading to improved agreement between measurements made by co-orbiting satellites.
Those are just some of the problems which lead to such large version changes.
Update: From a tweet from Carl Mears, here is a useful FAQ on the changes.
Further: David asked below about comparison with radiosondes. That FAQ has a diagram showing the comparison:
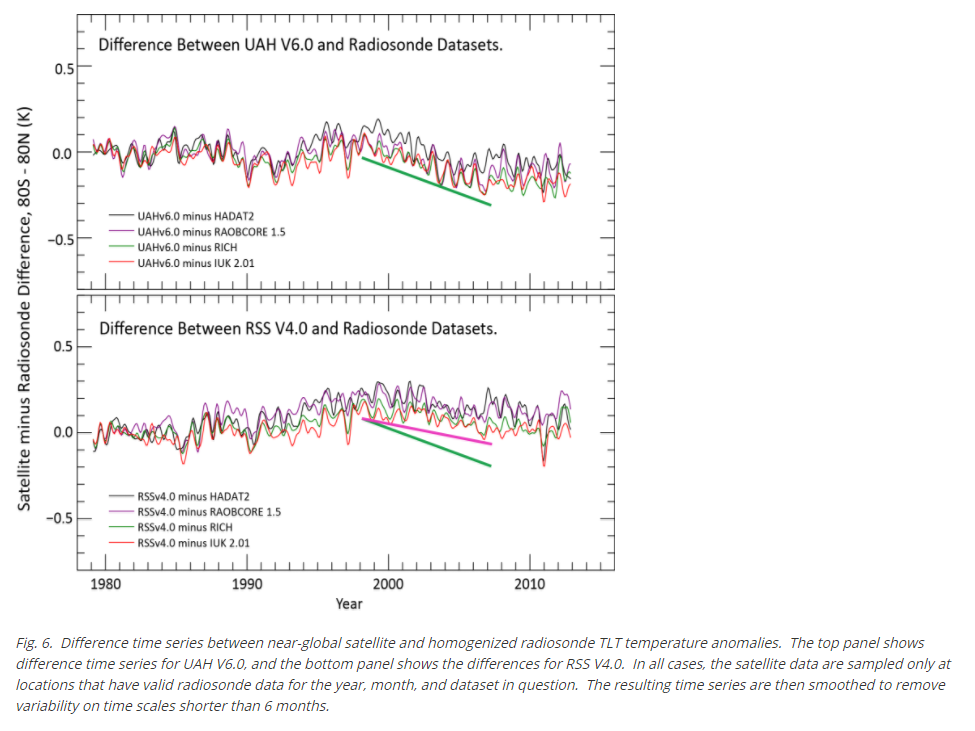
It is sat - sondes, so when you see in this century that the plot goes down, it means that radiosondes are showing more warming that satellites. With UAHV6.0 it is a lot more; with RSS TLT V4 it is closer, but sondes still show more warming. As the FAQ says:
"Note that all satellite data warm relative to radiosondes before about 2000, and then cool after about 2000. We don't know if this overall pattern is due to problems with the radiosonde data, with the satellite data or (most likely) both."













I take it that this is the same problem:
ReplyDeletehttp://www.independent.co.uk/news/science/climate-change-sceptics-satellite-data-correction-global-warming-140-per-cent-zeke-hausfather-a7816676.html
Are those guys even qualified to do this work? I am seriously perplexed by all this. From my own work, having calculated clock timing calibration and leap day corrections from GPS ephemeris data at my previous paid job, I can tell anyone that knowing precise satellite locations is critical. And for longer periods, the LOD drift that occurs over years is also important.
Like I said in a previous comment, NASA should have open-sourced the raw satellite data years ago instead of contracting it out. We could have easily done as good a job by using a combination of skills that these guys obviously lack. Did they do this because it has national security implications? I don't think so, cuz I didn't have a security clearance and recall working with mainly publically available ephemeris data and algorithms.
Now think in terms of ENSO and QBO models. Is it perhaps not a surprise that no one has determined that the biggest satellite of all has an impact on our climate? Only by keeping track of the moon's orbit to an insane precision will it make sense. Anyone can check the numbers and verify that a lunar-forced ENSO model (and QBO model) duplicates the cycles. It's physics feeding into geophysics and then climate out the backend.
Happy 4th of July everyone. It was the Frenchman Laplace back in 1776 that first came up with the tidal equations that bear his name and continue to be used in GCMs to this day. Maybe what we need is a return to first-principles modeling and essentially clean-room the models where necessary.
"Are those guys even qualified to do this work?"
DeleteI hope you are not suggesting NASA/science/RSS is to blame for this mess.
These satellites were designed to measure humidity to improve weather prediction. They were never intended to be used to monitor changes over decades in temperature. Scientists have warned many decades not to assume that these estimates are reliable, while political activists were cheering at the one outlier dataset and disingenuously claimed it was the only reliable one, especially in the beginning when only UAH was working on it and the dataset showed cooling due to a multitude of huge errors.
@Nick: I think beyond the problem of the diurnal drift, which is obviously a big source of systematic errors for the long term trend, there are other issues.
ReplyDeleteAs you said in the first point, there is only one (or a few) satellites at one time. So there is no global coverage, contrary to some claims. Although the satellite moves and the Earth rotates, there is only one measurement at one time. It is similar to having only one thermometer for surface measurements and traveling with this over the world to try to increase the coverage. Or better, like a sea surface temperature measurement using a single ship.
The next problem is that the satellites change rather fast, so each change of the satellite will cause an jump in the temperature data. So you have to connect the datasets which almost no overlap. A big source of error.
If a surface station moves or change the instrument or behavior, one has many, many other instruments that have not changed for decades for comparison.
Also the change from MSU to the AMSU units can introduce additional systematics.
So satellite measures are not naturally superior. The are far inferior to surface measurements, especially for long term trends, due to systematic errors that are at least an order of magnitude larger.
An other issue is that they can nor separate the (near) surface temperature change from the temperature in the higher troposphere. This is especially important, in cases of surface temperature inversions in the winter. So you can have large changes of temperature near the surface, due to different strong inversions, but little temperature change above.
If there is a long term trend is the strength of surface temperature inversions, the trend of (near) surface air temperature and the temperature of the air above may differ much.
In addition to that, I ask me, if the slightly changing content of oxygen in the atmosphere may contribute to a non-temperature related trend in the satellite microwave measurements. The oxygen content changes due changing water vapor and there is a long term downward trend due to the consumption of oxygen by burning fossil fuels.
I have a question:
Nick, do you know, if there is any correction for changing oxygen content mentioned in a paper of the RSS term (or others)?
I have not found any so far. And it seams to me as they assume that the oxygen content of the atmosphere is constant.
But intensity of the microwave signal does not only depend on temperature but also on the oxygen content. But I don't not exactly how.
If, for example, the strengths of the microwave signal would proportional to the oxygen content of the atmosphere, the lowering oxygen content would introduce a non-negligible cooling bias in the satellite temperature trend.
That may be all true, and the bottom-line then is that they don't have the most knoweledgeable people doing the work. I just tweeted to Carl Mears of RSS asking if this was a common-mode error between his team and UAH. The reason for contracting two teams is to reduce this possibility. If not that, they could have hired a second team to do independent testing. Either way should increase the confidence in the results -- what doesn't is to keep the source code under lock and key for years at a time.
DeleteBtw, Mears is actively tweeting right now on the topic.
But as far as how to do it if starting from scratch,I would go a different route. The departure point is to look at how well the satellite measurements agree with ENSO excursions. That is the calibration point I would start with. Match the height of the excursions as the first-order model and work from there.
What are they doing with thousands of lines of source code? What exactly are they patching up with all these statements?
No one was hired by NASA to do this. These satellite were never intended to monitor climatic changes in temperature; see above comment.
DeleteI am sure they had a contract at one time with either NASA or NOAA. Perhaps no longer, as I recall Spencer was belly-aching about lack of funding.
DeleteDARPA recently has funded projects that try to simplify the science, which is where I got my start. Easy to see what a boondoggle this has become. Like I said, its putting lipstick on a pig. And what magma said about watching a dancing bear. And then there is the observation that adding thousands of lines of code to an algorithm rarely makes it any better.
Here's a hurried and possibly wrong comparison of the standard deviations of the differences after removing annual cycle.
ReplyDeletedataset RSS3.3 RSS4.0 UAH5.6 UAH6.0
RSS3.3 0.000000 0.060937 0.135826 0.133119
RSS4.0 0.060937 0.000000 0.133347 0.145354
UAH5.6 0.135826 0.133347 0.000000 0.072871
UAH6.0 0.133119 0.145354 0.072871 0.000000
Interestingly the two RSS versions are similar to eachother, and the two UAH versions are similar to eachother. That's exactly the opposite of what you would expect from the trends. The cross dataset differences are dominated by a big noise-like signal.
Not much data around for O2 but it falls (and rises with Co2) the plots below are from me wondering what causes the CO2 yearly cycle.(I think it more likely to be phytoplankton rather than leaf growth and decay!):
ReplyDeletehttps://4.bp.blogspot.com/-UCcJgVJg-p8/T9plZES11JI/AAAAAAAAAYQ/w_u6fx5ySnY/s640/co2-o2.jpg
and
https://4.bp.blogspot.com/-bCvtAJzSBMY/T9ptnRzSP9I/AAAAAAAAAYc/1NYuolWUs_w/s640/co2+-+02+all.jpg
O2 data from
http://bluemoon.ucsd.edu/images/ALLo.pdf
or of course you could get the data here!!:
ReplyDeletehttp://scrippso2.ucsd.edu/osub2sub-data
Deconvolving the temperature and pressure-dependent 50-60 GHz oxygen emission spectra from a dozen partly overlapping satellites of different design to obtain some level of altitude-resolved atmospheric temperature time series is a remarkable technical achievement. Pretending that it is more reliable, precise and accurate than thousands of calibrated liquid-in-glass or platinum-resistance thermometers in fixed ground locations is not.
ReplyDeletehttps://disc.gsfc.nasa.gov/AIRS/documentation/amsu_instrument_guide.shtml
"The marvel is not that the bear dances well, but that the bear dances at all."
The bottom chart is particularly interesting. A couple of observations: 1) there is a lot of non-random variation among the series at a range of time scales so multiple "adjustments" are being handled differently, 2) some of the systematic variation appears to line-up with enso note the relatively weak response of the UAH series in the most recent nino, and 3) most of the UAH6 cooling bias occurs between 1998 and 2009 so may be due to the treatment of one or two satellites.
ReplyDeleteChubbs
"One consequence is that with satellites there is a big problem with the inevitable changeovers"is not a particularly good ref for "Particularly large differences between reconstructed temperature series occur at the few times when there is little temporal overlap between successive satellites, making intercalibration difficult."{{citation needed|date=April 2015}}
ReplyDeleteAnyone care to provide a ref for this or a rewritten version of it?
"Anyone care to provide a ref for this or a rewritten version of it?"
DeleteWell, here is Roy Spencer:
"Since 1979 we have had 15 satellites that lasted various lengths of time, having slightly different calibration (requiring intercalibration between satellites), some of which drifted in their calibration, slightly different channel frequencies (and thus weighting functions), and generally on satellite platforms whose orbits drift and thus observe at somewhat different local times of day in different years. All data adjustments required to correct for these changes involve decisions regarding methodology, and different methodologies will lead to somewhat different results. This is the unavoidable situation when dealing with less than perfect data."
Nice of you to add to the wikipedia page. Will the link to this blog post eventually get removed? They typically do because they say that blog science is not real science :)
DeleteMears says they calculate the diurnal correction separately for ocean and land by latitude. Whatever makes the differences between contemporaneous satellites go away is assumed to be most correct. The diurnal correction over ocean is small, while the correction over land is comparatively large. Since proximity to land/ocean would presumably have an affect would it not be more accurate to calculate the corrections based on a grid? Or would that be computationally difficult, or create more noise than its worth?
ReplyDeleteOr the type of surface and changes in the type of surface. Brown desert vs dark forest for example. Or the amount and change in pollution over an area. How does the "Asian brown cloud" affect the diurnal temperature change of the troposphere?
DeleteNick, Isn't there a lot of radiosonde data that more or less agrees with the satellite data? My impression, perhaps wrong, is that both show a slower rate of warming than models predict.
ReplyDeleteDavid,
DeleteI have added an extract from the FAQ on that, with a diagram. It shows that for this century, radiosondes show more warming that satellites, but RSS is closer. How that matches with models, I don't know. What I usually see when people talk about that is comparisons with model surface predictions. What models say about the lower troposphere is rarely shown.
David Young, yes I would agree with you that your impression is wrong.
DeleteYes Nick, I think the models show a substantially faster warming rate aloft than at the surface. And that is even illustrated on Real Climate where they have a graph doing the comparison. Even with their choice of baselining, there is a very wide gap.
DeleteThe problem here is that the lapse rate theory which the models match is a cornerstone of our understanding of the greenhouse effect. That's a problem that should be addressed it seems to me.
DeleteI suspect this has something to do with our lack of understanding of convection and relative humidity in the tropics. issac Held has a good post on modeling convection showing some rather alarming sensitivity to size of the computational domain.
Delete"Lack of understanding"
Delete???
David Young, I think it's your constant yapping about the computational fluid dynamics being too hard.
Not so much. Try to find the research that showed that lunar forcing isn't a driver for the equatorial climate dynamics.
http://contextearth.com/2017/06/23/ensoqbo-elevator-pitch/
Isaac Held and his fluid dynamics lab at Princeton are not following NASA JPL's lead concentrating on the external forcing, but instead wasting their time on micro mechanisms such as convection. That's not the stuff that generates the large dynamic swings in climate!
So recall the mechanism that keeps your Boeing plane aloft is not Bernoulli's principle but the concentrated fossil fuel created by millions of years of the sun's external energy beating down on the earth.
That's also why CO2 is a threat. But you are too wrapped up in your myopic worldview to understand that.
The reference below indicates that models agree well with radiosondes when proper comparisons are made except for the highest layer (150mb) where ozone is important. Olaf R has produced a few charts also showing good agreement between models and radiosonde except for the stratosphere where the obs have cooled relative to the models probably due to errors in specifying ozone.
Deletehttp://onlinelibrary.wiley.com/doi/10.1002/grl.50465/epdf
Chubbs
David,
DeleteThe RC plot of TMT comparison is here. It stops in 2015, about the end of the slowdown. If you extend it to present, the observations are well within the range of the models, though in the lower half.
But they too don't have a plot of TLT prediction, and I can't remember seeing one anywhere. I'll show a plot, probably tomorrow, of the updated TMT data superimposed on the RC TMT plot.
Nick,
DeleteSanter, et. al. (2017) TMT models versus satellites (includes the NOAA STAR and RSS groups as coauthors is here) ...
www.meteo.psu.edu/holocene/public_html/Mann/articles/articles/SanterEtAlNatureGeosci17.pdf
web.science.unsw.edu.au/~matthew/Santer_et_al-2017-Nature_Geoscience_SI.pdf
pcmdi.llnl.gov/research/DandA/Synthetic%20Microwave%20Sounding%20Unit%20(MSU)%20temperatures/2017/Nature_Geoscience/NG_Fact_sheet_v3.pdf
(paper, SOM/SI and fact sheet)
No TLT vs models AFAIK.
Nick, see also this directory ...
Deletehttps://pcmdi.llnl.gov/research/DandA/Synthetic%20Microwave%20Sounding%20Unit%20(MSU)%20temperatures/2017/Nature_Geoscience/
The *TLO* files look like the global monthly time series (e. g. to reproduce say Santer's Figure 1), while the *GLB3/GLB2 look like 2D gridded data files.
Thanks, Everett, That could be very useful.
DeleteNick,
DeleteI'm not exactly sure what the *GLB3* and *GLB2* files are now, just found them like five minutes age, the GLB files look more like the model run monthly time series for TLT and TMT (all files start as tlt* or tmt*). So not 2D gridded.
Everett,
DeleteI downloaded the hist_rcp85_37m_tlt-GLB3_cesm1_cam5_r1i1p1_r1979_2016_s1979_2016_nofilt.d file. Each has an explanatory section at the front. It's just a time series (3021 months to 2100AD), which I think is the TLT-weighted global monthly average.
Yes. TLO2 is TMT tropics (20S-20N), GLB2 is TLT global (70S-82.5N) and GLB2 is TMT global (82.5S-82.5N). Baseline is 1979-2016 (inclusive or 38-year baseline for anomalies).
DeleteThe three picontrol (pre-industrial or no homo sapiens) tar files DO NOT have a mean global time series. While all other tars have a mean global time series from the 36 individual CMIP5 runs.
I think I'll look into the two (TLT and TMT) 36-model mean time series versus UAH, RSS and NOAA (using 1979-2016 baseline).
Rats!
DeleteAbove comment ...
"GLB2 is TLT global"
should be ...
"GLB3 is TLT global"
The RSS chart with comparison of radiosonde and satellite data that Nick added is a little bit disturbing due to the prominent seasonal swings in the differences. I recommend annual data or 12 m running means for clarity.
DeleteHere is a similar comparison between Ratpac A and UAH v6 TLT, with original global datasets and "apples-to-apples":
https://drive.google.com/open?id=0B_dL1shkWewaRXJzeHhfWG54VEU
RSS TLT v4 would behave better in the AMSU era compared to sondes, but the TLT-product with the highest trend in the AMSU-era is still UAH 5.6
UAH 5.6 doesn't use diurnal drift correction in AMSU's, but relies on non-drifing satellites.
AFAIK UAH 5.6 also suffer from the "Cadillac calibration cherry-pick", where Spencer & Christy claim that low-trending NOAA-15 is right and NOAA-14 wrong without any supporting evidence. All comparisons, with radisondes, reanalyses, neighbour satellite channels, etc, suggests that this "cherry-pick" is wrong and NOAA-14 is right. Here's one comparison with neighbour satellite channels:
https://drive.google.com/open?id=0B_dL1shkWewaSkpnOUxBVGNpWm8
If you excuse my sarcastic tone, I think that the "cherry-pick" by the UAH team is scientific misconduct, or the scientific equivalent to the infamous "Hand of God" by Maradona in FIFA world cup 1986.
The additional similarity is of course "not spotted by the referees".
World cup matches cannot be replayed, but science can be corrected afterwards..
Handball by Roy, lol. And Sagan "elbowed" Cav while Cav hooked his handlebars as he was going down.
DeleteExactly, science is self-correcting.
Couple of surprising features I've noticed. The V4 TLT CONUS average appears to show a very slightly larger linear trend than most surface CONUS records, which is quite a big change from the previous version. I would tend to expect a continental mid-latitude region to warm less aloft. Indeed inter-annual variations show noticeably greater amplitude at the surface.
ReplyDeleteIn the Tropics, Po-Chedley and Fu 2012 previously pointed out that satellite-model discrepancies weren't just a matter of surface vs. troposphere. The MSU/AMSU products were also finding a significantly lower TTT/TLT ratio than all models suggested should be the case, indicating that the Upper Troposphere was not warming quite as fast as expected in comparison to the Mid Troposphere, at least during the 1981-2008 period of study.
According to the RSS widget V4 TLT in the Tropics shows only a slightly larger trend than V3.3 during 1981-2008, whereas the increase is considerably greater for TTT. These changes shift the TTT/TLT ratio higher, but it's also now significantly higher than all but one outlier model. Seems like it would be worth figuring out how that happened.
Couple of caveats to that. The Tropics area used in the RSS widget is 25S-25N, whereas Po-Chedley and Fu used 20S-20N. Also I believe the derived vertical weightings for the new RSS V4 products are different from V3.3 so you'd have to apply those to the model data for a more accurate comparison. I could be wrong but I expect those things won't make a big difference.
"Stuff happens". The UAH6/RSS4 comparison may no longer be valid. The June UAH update says
ReplyDeletehttp://www.drroyspencer.com/2017/07/uah-global-temperature-update-for-june-2017-0-21-deg-c/
> NOTE: We have added the Metop-B satellite to the
> processing stream, with data since mid-2013. The
> Metop-B satellite has its orbit actively maintained,
> so the AMSU data from it does not require
> corrections from orbit decay or diurnal drift. As a
> result of adding this satellite, most of the monthly
> anomalies since mid-2013 have changed, by typically
> a few hundredths of a degree C. The 1979-2017 linear
> trend remains at +0.12 C/decade.
What actually got my attention, was the bolded statement
"Lowest global temperature anomaly in last 2 years (since July, 2015)"
I remembered March 2017 being lower. I checked last month's download, and it showed March as +0.186. But Dr. Spencer's blog post now shows March at +0.23. The blog post gives URLs for 2-digit data. I prefer 3-digit data from http://www.nsstc.uah.edu/data/msu/v6.0/tlt/tltglhmam_6.0.txt
It'll be interesting to see how much the UAH6/RSS4 comparison changes once the final data comes in. I expect it to arrive approximately 7th to 10th of July.
Walter Dnes
I think the problem is the vertical temperature profile in the tropics where lapse rate theory is very definite about what should happen. There was an old paper trying to reconcile sonde data with climate models. It seemed quite implausible to me as I recall and tried to use wind speed as a proxy for temperature despite the fact that temperature was directly measured.
ReplyDeleteDavid,
DeleteSounds like you are talking about this paper by Sherwood et al. It doesn't use wind speed as a proxy. It uses it to help detect changepoints, for homogenization. An issue with radiosondes is solar heating. They aren't carrying a Stevenson screen. Wind speed is measured mainly from the path of the balloon.
The problem is one of confirmation bias. Climate science hacks such as Tsonis, Curry, Lindzen never did the groundwork to eliminate lunar forcing as a mechanism for variability. They all just assumed it couldn't be a factor. Whether this is confirmation bias borne of ignorance or of deeply entrenched conventional wisdom I don't know, because I am not part of that culture.
DeleteBut notice that David Young also claims to be an outsider looking in, yet blissfully ignores others with alternative views. That's obviously because he has a political agenda rather than a scientific one. A political confirmation bias rather than a scientific one. He zeroes in only on questions that cast doubt as opposed to foster progress.
David,
DeleteIf we focus on the recent 20 years, the period with the alleged pause where satellites and models don't agree, I would say that radiosonde data and models agree quite well in the lower half of the atmosphere, but is cooler in the upper troposphere and above.
Here's a pressure level temp comparison with Ratpac A data and CMIP5 averages for 1997-1016 (It's a good period because it's ENSO-balanced with one strong el Nino in the beginning and one in the end)
https://drive.google.com/open?id=0B_dL1shkWewaVDBEb3ctNDFZV2M
I admit that the observed tropical hotspot is weaker than the model average in the recent decades, e g the satellite era.
However, I think that the explanation is stronger trade winds and cooler tropical SST compared to models. In the following chart I have used the tropical 200 mbar pressure altitude as a hotspot index (much easier to download compared to taz)and compared it with the Nino 3.4 SST
https://drive.google.com/open?id=0B_dL1shkWewaTXJJSExKRjBhbVE
The Nino 3.4 trend is almost flat in real world, unlike models, and the troposphere "rise" (hotspot) is also lower than all models.
I believe that real world warms more "la Nina-like" than models , characterized by stronger trade winds and more transport of heat to higher latitudes and to deep ocean, resulting in a weak hotspot.
If we pick a period with similar observed and model average trend in Nino 3.4 SST, e g 2000-2016, the 200 mbar altitude trends are quite similar. However the 2000-2016 period is not very well ENSO balanced..
The other problem is about treating the symptom rather than the cause. Can you imagine if we were discussing how accurately we are measuring tidal levels rather than understanding what was causing the tides? Yet, that's exactly what is happening with our misguided focus on measuring the side-effects of ENSO. All it takes is two measurements, one at Darwin and one at tTahiti, to estimate the impact of ENSO. That part is done. Now we should be concentrating on the analysis of the tidal forces. The misdirections by Tsonis and David Young are diversions. Tsonis especially, with his chaos diversion has halted progress. The point at which one cites chaos as a mechanism is a stop sign to all others intending to do research. We really have to exhaust all the other possibilities before chaos theory is invoked. Too bad, but it is never too late to get on the right track.
DeleteSee also: Missing the plot. Going off on a tangent.
Mears has updated the climate write-up on the RSS site to reflect v4. As expected v4 is in better agreement with CMIP5 but still in the lower portion of the CMIP5 envelop. There is also an interesting comparison of satellite temperature and water vapor data. Below is a quote:
ReplyDelete"The bottom panel shows the ratio of the vapor trend to the TLT trend. Climate models suggest that this ratio should be about 6.2%/K. All combinations of satellite dataset show larger ratio, suggesting that either the measurements show too much moistneing, or too little warming. The most recent version of the RSS TLT dataset is closest to expectations. This is Figure 13 in Mears and Wentz (2017)"
http://www.remss.com/research/climate#vapor
Chubbs
Olof R on July 6, 2017 at 8:46 PM
ReplyDeleteHello Olof,
I apologize, but I really don't like the format of these charts.
They remember me the "occultistic" language used by medicine people who like to talk of enteroscopy instead of gut examination :-(
What about charts like this one?
http://fs5.directupload.net/images/170711/ew6xbnle.jpg
Btw: you certainly remember this boring discussion at Climate Audit concerning the 18 cell subsampling of UAH, completely mislead by this Dr Browning.
All R code sequences there referred to a latitude weighting based on cosines.
I have problems with that weighting.
Could you please have a look at a comment posted at Roy Spencer's site:
http://www.drroyspencer.com/2017/07/comments-on-the-new-rss-lower-tropospheric-temperature-dataset/#comment-254861
and tell me what you think about it?
Bindidon, Nice ski jump slopes :-) with a tiny hotspot in the tropics..
DeleteRegarding area weighted data: When you have summed all weighted latitude bands, you must divide the result with the sum of all weights you have used.
If you don't do this, and the sum of weights is 2 for instance, the temperature span and trend will become twice as large than the correct one..
Thanks Olof, Nick explained me the same stuff in a mail.
DeleteBut concerning the temperature span and trend will become twice as large than the correct one: the cosine calculation I found in the net divided by the number of latitudes, and not by the sum of the cosines. That was obviously wrong.